Zadáním od pana Ing. Daniela Tihelky, Ph. D bylo vytvoření "pluginu" pro jednotné rozhraní k řečové syntéze Speech Dispatcher (Od softwarové laboratoře Free(b) Soft) tak, aby toto rozhraní pracující pod operačním systémem Linux mohlo využívat ke hlasové syntéze (v českém jazyce) syntetizér vyvinutý na Katedře kybernetiky Fakulty aplikovaných věd Západočeské univerzity v Plzni.
Rozsah této práce byl předem těžko určitelný. K dispozici jsem měl zdrojové kódy (málo komentované) a dokumentaci ke Speech Dispatcheru (o které ještě bude řeč později), zdrojové kódy dummy knihovny katedrálního syntetizéru (dobře komentované) a zdrojové kódy rozdělaného "pluginu" od jiného studenta, který na úkolu v minulosti pracoval. Tyto zdrojové kódy na mém počítači nešly přeložit. Objevovalo se spoustu chybějících referencí v souborech od Free(b) softu, i když byly podle všeho všechny potřebné knihovny a soubory pro vývoj na mém počítači přítomny.
Po nastudování dokumentace a prozkoumání možností jsem pana Ing. Tihelku informoval o možnostech a požadavcích Speech Dispatcheru a výstupních modulů, které poskytují rozhraní pro komunikaci Dispatcheru s různými syntetizéry.
Standardním postupem při přidávání podpory nového syntetizéru Speech Dispatcherem (dále i jen jako spd) je vytvoření právě takového výstupního modulu podle specifikací daných dokumentací ke spd a syntetizérem, který se považuje za již hotovou samostatnou aplikaci. V našem případě je syntetizér přítomen jako knihovna a je tedy možné vytvořit exekutivu, která bude tuto knihovnu využívat a vzhledem ke Speech Dispatcheru chovat jako výstupní modul. Zvolili jsme tedy tuto cestu.
Při výše uvedeném řešení je třeba dát pozor na licencování, protože plná verze knihovny syntetizéru je distribuována jako uzavřený kód a Speech Dispatcher, včetně skeletů výstupních modulů s ním poskytovaných je open source pod licencí GPL verze 2. Není tedy možné volat GPL kód z ne-GPL kódu, pokud držitel dané GPL licence neučiní výjimku.
Ve finálním stavu by modul/syntetizér měl umožňovat běh syntetizéru a přehrávače v samostatných vláknech a umožnit přehrávání již vysyntetizovaných vzorků s případnou pokračující syntézou na pozadí (hlavně u delších textů).
modře: probíhající syntéza, červeně: probíhající přehrávání
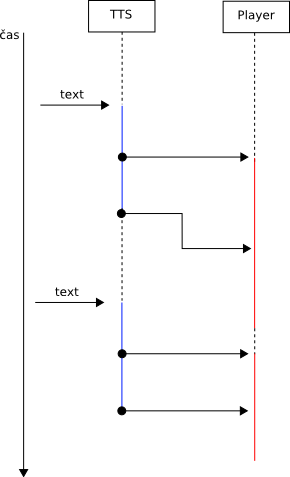
Přerušení přehrávání při příchodu zprávy s vyšší prioritou nebylo zatím řešeno. Mělo by být však v režii spd.
Modul/syntetizér vyvíjím jako součást Spech Dispatcheru, tedy ve složce se zdrojovými kódy ostatních výstupních modulů za použití původních souborů pro řízení překladu upravených pro moji potřebu.
DBG() uváděné v dokumentaci pro provádění ladicích výpisů není funkční. Dokonce i výstupní modul pro espeak, který je součástí Speech Dispatcheru v distribučních balíčcích neprovádí ladicí výpisy z míst, kde je použito makro DBG(), ale pouze tam, kde je používáno makro MSG(). Možnost použití funkčního makra MSG() jsem se dozvěděl z changelogu nalezeného na internetu a datovaného do roku 2005.INIT_DEBUG() ve funkci module_init(), jak je uvedeno v dokumentaci (Chybí reference). Ve zdrojových kódech aktuálních výstupních modulů se INIT_DEBUG() nevyskytuje.DBG() na MSG() i v použitých podpůrných zdrojových souborech poskytovaných Free(b) Softem.(Cesty jsou relativní ke složce SpeechTech)
sudo apt-get install python-speechd).Zde jsou uvedeny požadavky kladené na syntetizér při tomto řešení.
pthread_cond_signal() call unblocks at least one of the threads that are blocked on the specified condition variable cond (if any threads are blocked on cond).pthread_cond_wait() and pthread_cond_timedwait() functions are used to block on a condition variable. They are called with mutex locked by the calling thread or undefined behaviour will result. pthread_mutex_lock() vrací výsledek teprve tehdy, pokud se podařilo vlákno zamknout. V opačném případě ve funkci program zůstane "viset". Pokud po požadováno, aby při zamykání mutexu byl návrat z funkce okamžitý, je třeba použít funkci pthread_mutex_trylock() . Pak je dobré testovat návratovou hodnotu, zda bylo zamčení úspěšné, nebo ne.